
Years ago I started off working in military (Military Policeman, Graphic Artist, and then Typesetter). From a personal perspective, I picked up a Timex/Sinclair Z80 computer. It needed a cassette player to save data to cassette and plug into a TV. After the military I did some odd jobs (car salesman and security guard) to make ends meet and wrote programs to make the job better (flash card like program for car salesmen and vehicle manager for the security guard). I finally got a job as a part time programmer, moved into full time programming, into LAN administration, and then managing Unix Systems. During my part time programming job, I attended a set of classes that taught Structured Programming. I liked the concepts and applied them to my current job and even more at my first full time programming job. I spent some of my own time rewriting the modules of the program I was maintaining and improving (Funeral Home Software) to make it better and easier to maintain. Each section had an initialization section, data retrieval, display (for editing), and printing sections. There are always exceptions of course but in general I rewrote the code to make it easy to maintain and locate bugs (and I did find a few and some logic issues; someone didn’t know how to create a loop so duplicated a block of code 10 times).
At that job I added the installation of networks and managing LANs, then went full time as a LAN admin. When the job ended, I started working as a Senior Telephone Tech Support person working with great people like John McKewon, Ron Sitnick, and Omar Fink. I learned how to use a database (Paradox) to manage tickets, then moved into a job as a DBA working on r:Base and the EIS with Bill Beers, and then as the company’s first full time LAN administrator working on 3+Share for Steve Horton. I significantly improved the configuration and I continued my programming interest by working on various tools to improve my job. I created a menu configuration tool that created a configuration files for 3+Menus and a tool that crossed domains to get information. Of course I continued my personal fun and wrote programs for gaming purposes and as plugins for bulletin boards.
Next I started working at Johns Hopkins APL where I gained access to Usenet. I was managing the Administrator’s network and teaching the new folks how to administer 3+Share (they’d had classes 6 months earlier but hadn’t touched it since then so refresher). To keep me occupied, I created a Usenet Reader. I’d gained access to Usenet and in learning how to create the reader, I learned quite a bit about RFCs and return codes from internet services (like usenet). When I started with Bulletin Board software, I’d downloaded a game called Hack and then Nethack. Access to Usenet gave me lots of interesting discussion groups, one of which was the nethack group (alt.games.nethack I think). After loads of discussion, I was approached to see if I was interested in helping with the coding of Nethack. It was maintenance stuff, minor bugs in how things worked and nothing really big but still pretty cool.
One of my personal projects was working on a long time program of mine (The Computerized Dungeon Master). In looking to improve it, I found Mike Smedley’s CXL text windowing library. There were others I checked out but this was the only one that I could get working. Norton had a Norton popup tool called Norton Guides with various documentation subjects like C programming (which I was doing). Someone had provided a tool to reverse engineer the databases and create new ones. I created a popup for the CXL API so when I was working on my program, I could just pop up and check the API. Along with the API, I added other bits of information I used when writing my code like line drawing characters, etc. When CXL was purchased by another company (TesSeRact (TSR)), they converted CXL to TCXL and worked to make it cross platform, Windows, OS/2, Unix. While an interesting project, I was more interested in the PC part of course and I spent a bit of time converting and creating a Norton Guides db for TCXL. I also spent a lot of time digging into the header files to find functions and see what they might do. Lots of behind the scenes work by the windowing software. I was rewarded with a phone call asking if I’d proofread the next major version vs waiting for me to pop up on the BBS and provide errors 🙂 I was also brought up to Pennsylvania to hang with the crew and President of the company.
When I started working at NASA, the previous admin (Llarna Burnett) left a notebook called “Processes and Procedures” with some documentation on managing the network. Up to then and while I was managing the International Relations LAN, I was the sole programmer or network admin. I was honestly puzzled as to what the difference was between the two and what I’d even write. Procedures I could understand but Processes were a bit harder to grasp. I did do some research to try and understand but as a loner, I still didn’t fully get it. I continued on managing the network and interacting with other groups at NASA. Eventually I needed to move to the central group as the environment changed, into a centrally managed group. As my servers transitioned, I found I was going to be a Windows NT LAN manager and only responsible for printers, shares, and users. This was my first time working with others of my profession as well. I decided to move on as this wasn’t interesting. The manager (Bill Eichman) and the Unix admin (Kevin Sarver) came to me, not wanting to lose my knowledge and skills (I guess 🙂 ) and asked me if I’d consider being a Unix admin vs moving on. I actually thought about this for about a week. I already had a job lined up as a Novell admin if I wanted it but I’d been mucking about with Linux for several years and of course had access to Usenet and written a Usenet Reader so I took them up on the offer. The first month was spent on the Usenet server and Essential System Administration (AEleen Frisch; I even submitted a correction to her 🙂 ).
Kevin had taken over the Unix environment and documented quite a bit of the servers plus made things work better but he’d documented it in notebooks and stuck them in file folders. Since he’s a senior, I sometimes (most times 🙂 ) had a hard time understanding what he was writing and in many cases, the information was outdated or there wasn’t enough information, just additional notes (“it’s obvious” 🙂 ). As a programmer type and with Norton Guides I’d used in the past, I much prefer having the docs in digital format and at my fingertips. So as I learned what each of the systems did, I wrote up my findings on a website.
I created a ‘Version Description Document’ (VDD) for each of the servers with links to docs and scripts, and had a ‘gather’ directory for captures of server information and documentation on how to achieve common tasks and troubleshooting steps on how to recover if necessary. I write docs and scripts as if I’m going to be hit by a bus so they’re as complete as possible and clear. Since I had other admins on the team (Victor Iriarte), I wanted them to be able to work if I was unavailable but I also wanted them to feel free to make updates if needed. (We worked with Windows guys too; Ed Majkowski and Tim.)
Developers would create their application software for the various ‘Codes’ at NASA (a ‘Code’ is the same as a department) and my team would manage and install the software based on Change Package. In order to not have applications get lost and so the app guys and Code’s knew the status of the deployments, I created a web page with projects and their status. The digital docs were stored in the server directories.
One of the things Victor did was work to expand my limits on what to document. When I became the contract Engineer, I would review all Change Packages. Victor would ask for missing information and in thinking about it, I’d agree, we need the additional docs in order to properly install and manage the applications. One of the incidents I recall is a new package that had a requirement for a newer version of Perl. Unfortunately the system had other applications and tools that may use Perl (we used Cold Fusion for the web site) so there was a big to-do over investigating the existing applications to ensure they worked with the newer version of Perl and instructions to the developer to make sure they communicated those requirements in the future.
I worked at NASA for 13 years before moving to Colorado. I enjoyed working there but a series of visits to Colorado and the sudden death of Edwin Smith (the manager brought in to convert the NASA contract from Red to Green) had me looking for a less stressful environment. The drive to downtown Washington DC and home and general area issues just were pretty bad.
Amusingly, I returned a year later on a visit and while I was visiting, the current Unix Admin team (of which I knew none of) found out it was me and all came over shaking my hand and thanking me profusely for the documentation I’d done and the web site. It was pretty gratifying I must say 🙂
In Colorado I got a contracting job with IBM in Boulder. While a stressful place to work, I continued my efforts to document systems. Of course there are plenty of docs there but I brought my own skills to the plate and greatly expanded the effort creating new pages and making sure the team created their own pages plus provided a gathering place for the existing documentation. I also expanded my own skills in writing web pages including starting to use PHP. I created a pager page (select a user from a list and send out a page) and various documentation pages. The site at IBM was much more involved and I had a hand in creating a directory structure for all servers and data capture with historical information. IBM used tools such as ‘Tonic’ to check environments for configuration issues and ‘lssecfixes’ for security scanning. I started the captures and stored the information on the central server for review.
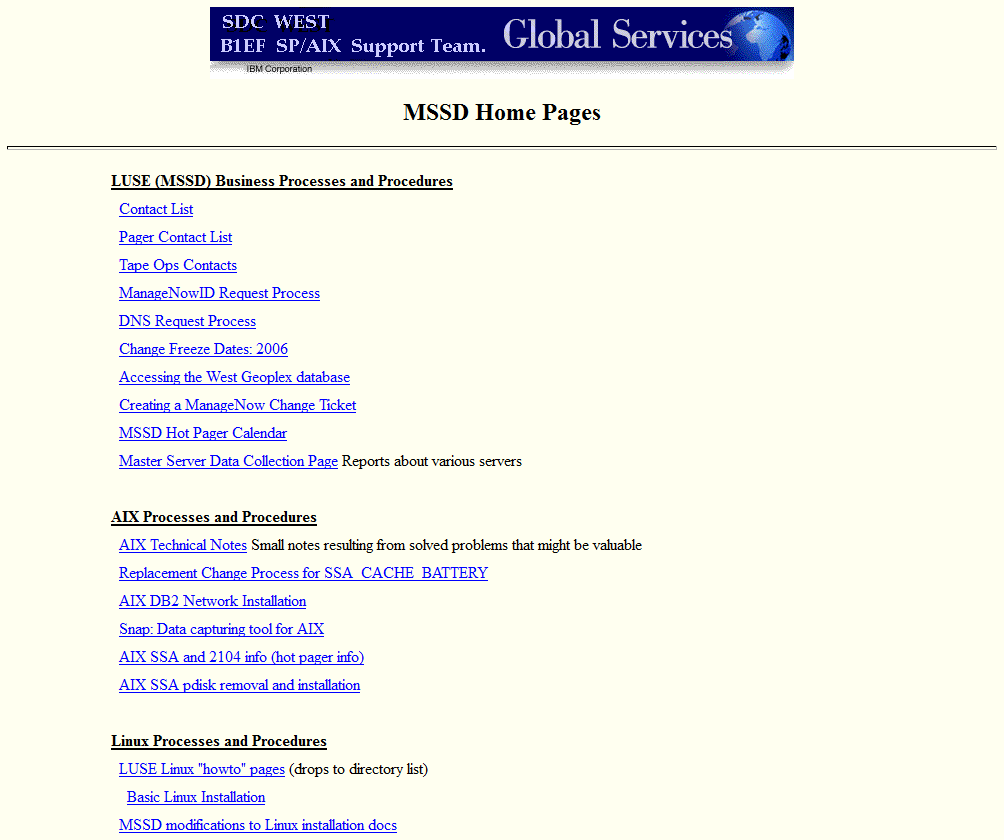
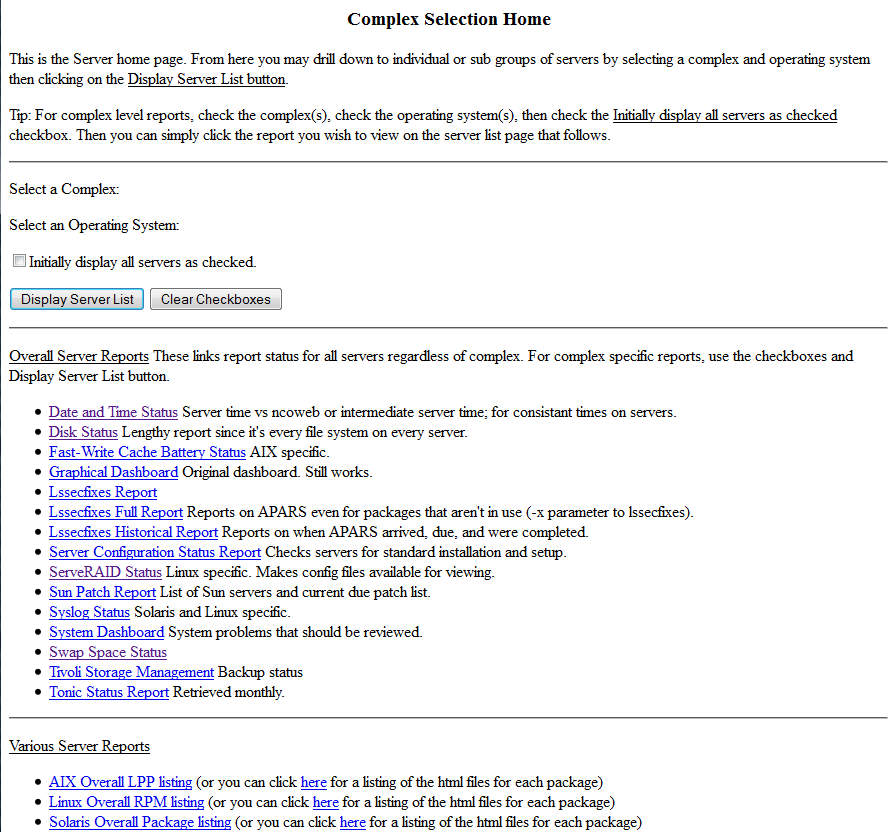
I really did expand my skills in data capture and management and in creating processes and procedures. The pages at IBM look much better than the NASA pages but the functionality is pretty similar. Web site for processes and procedures and automatic data capture. One of the cool things is the Tonic tool. I was brought in as a Solaris expert and Tonic didn’t really have much of anything on the Solaris side. So I spent a lot of time updating scripts and passing them along to the folks in England who supported the tool. After a year or so, I was contacted and asked if I wanted to be on the team. These two guys never let anyone outside of England much less the two guys who maintained it to join the team so I was pretty honored to be asked.
But the contact changed and I moved to a new team. These guys supported a company in Boston so I spent a year working from home. This was actually pretty bad in that they didn’t like anyone doing things like the documentation I liked to have on hand and I was called a ‘Cowboy’ for trying to do so. I did spend some time working on their tool which was used to manage the environment but I was pretty dissatisfied and the contract, and IBM was pretty toxic in the way employees and especially contractors were treated. Eventually I left and joined the company I currently work at.
When I started at the current company, the team had 6 members but documentation consisted of a block of hundreds of emails that were forwarded to new folks and one of the guys had created a spreadsheet of the systems primarily in order to do a data center walk through. The information was pretty spread out and perhaps difficult to find. There was a lot of room for improvement 🙂
I started by creating a list of servers similar to what I had at IBM (yes, I brought my skills from NASA and IBM here, why not 🙂 ) and used that to start investigating systems. I created a wiki server using Media wiki to start documenting our processes. IBM had a similar server specific site but I couldn’t use that and had been poking at wiki software to that point. The new wiki server was much better than sending a bunch of email 🙂 I also converted the spreadsheet into a simple database. I’d created a Status Management database earlier to manage the weekly status reports management wanted so used a similar process to create the server database. This was the first time working with mysql and I was starting to do some poking about with CSS and more PHP coding.
The first mysql server database was a list of servers (basically a straight import of the spreadsheet) and editing a server brought up a single edit page. At the bottom was a password requirements in order to make a change. The password was hard coded into the page though. The passed password and the stored one was compared and if it matched, the update was made 🙂 Pretty simple actually and horribly insecure but it got the job done.
In the mean time, I started gaming again and part of the gaming was thinking about my TCDM program I’d worked on years before. The game was pretty intense with lots of modifiers so I created a set of Javascript based pages that let me plug in information and have it automatically generate a final result. They actually worked pretty well and I used them when running my games.
I also used it when I started expanding the server database. This was still a single database with some expansion into new territory but it was getting better. After a bit, I wanted to create a login system to manage users but was having a hard time getting that understood and working and eventually just bought a login system package. At the same time, I started the conversion to Inventory 2.0. This involved breaking various bits of the main server database into sub-tables. Hardware to it’s own list associated with the main table. Network information (interfaces) associated with a server, and continued down that path.
I also snagged the CSS file from the phpinfo() page to give me a starting point for making changes to the site. Rounded corners on stuff, shadows, managing screen space. Initially the page was a fixed width but I learned how to create a page that expands with the width of the browser. There was a bit of learning as I changed how I thought about web pages themselves and HTML and trying to get the site to work with Internet Explorer. At one point I created a Convention management site because of the problems with a local gaming convention and came upon some information that let me better design the inventory at work. I also used the work and convention info to rework my personal inventory site. There is lots and lots of bleed over between my personal stuff and work stuff. 🙂
As I continued, I was tasked with creating a Rapid Server Deployment set of scripts. We’d taken the individual bits from the various teams, organized it into a flowchart, and then I took the flow and created the module to the inventory. That’s been a bunch of work but it has improved the deployment speed other than the normal delays with getting good documentation for the project deployments and getting configuration information quickly and accurately from other groups.
Back in August of last year, I started the process of reviewing the inventory with an eye to making things work more consistently. I already had a Coding Standard page I’d written with templates on how to create the various bits in the Inventory to make things consistent. One of the admins was a stickler on consistent and helpful user interfaces so I spent time working that out in my head and then in December, started the project of converting the existing Inventory 2.x system to Inventory 3.0. Part of that was learning a bit of jQuery as well. As much for the tabbing feature, which I thought was cool, as for the ability to theme the site. In the process of conversion, I found many errors. I monitored the error log and created a php error log and addressed every single error I found. Initially it was a lot but eventually I got it down to almost none (there are some things I can’t fix). Not only did it make the site more consistent, it also made it simple to identify mistakes in the code.
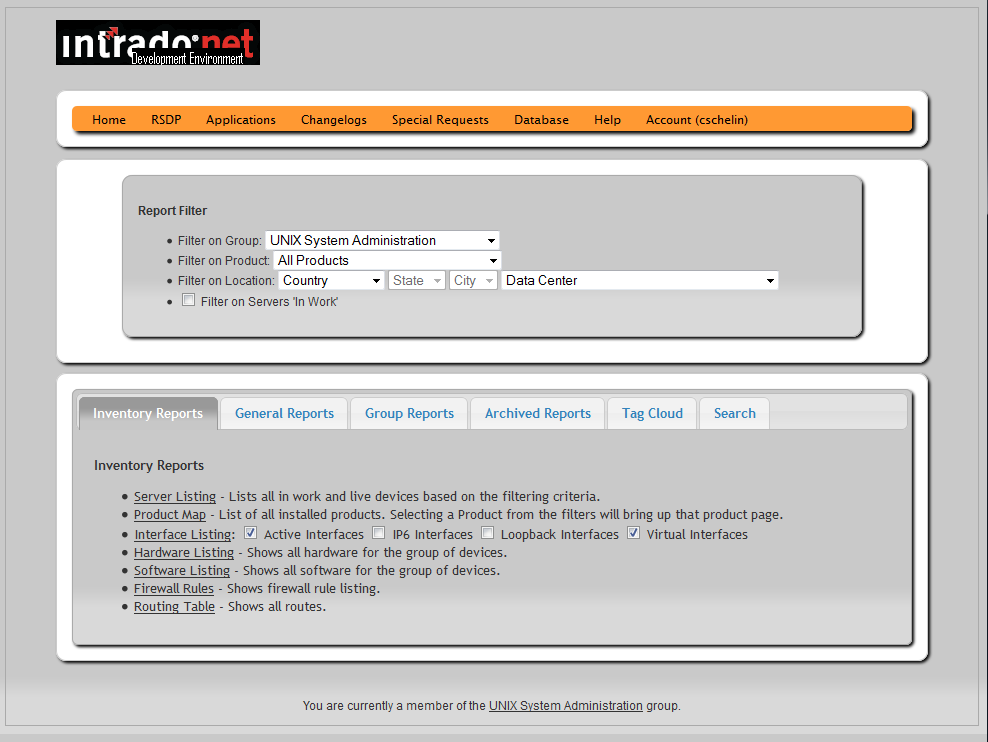
The new site has almost 100,000 lines of PHP code (well, comments, blank lines included 🙂 ) and over 400 scripts. The database has 114 tables (lots of little drop down menu management tables too). I’m quite pleased at how it looks and functions and even with a few errors popping up, it’s been a lot easier to fix.
And after years of “we won’t use it because it’s not official” comments, the powers that be have ruled that my Inventory database has the most accurate information to be imported into the new official ‘asset tracking system’.
I did almost all the coding of the inventory on my own time, to satisfy a personal itch, to make my job easier. That’s the same thing I’ve done in the past with the projects at NASA and IBM. I’m working to make things easier for me and my team. It’s always been, “here’s the documentation, here’s the list of equipment, use it or not”. Part of the issue with folks using the app was the ‘use it or not’ attitude. But I cannot make someone else use the tools I create. All I can do is make it available for use.
As time moved on, I continued to upgrade the Inventory and started cleaning up the code to be more efficient. I’d been checking out other inventory programs and they were mainly desktop oriented but there were interesting ideas. I also checked out some IPAM tools. Eventually my goal is that the Inventory is less a tool that retrieves information and now a tool that defines the environment. It does pull information from systems but the goal is to build systems in the Inventory and create the scripts used to build and manage servers.
Part of this view was exposure to DevOps and Infrastructure as Code. This included using Ansible to replace monitoring scripts. I started working with Kubernetes at 1.2 for a product deployment. This required learning about containers and orchestration which expanded my Infrastructure as Code knowledge.
At this point I left the company to join a new one which let me expand my IaC skills to the point where I was able to convert a 100 server build for a project that took about 14 months to complete, to automation that reduced the 100 server build to 90 minutes. And of course I created a ton of documentation for the process.